데이터 시각화
※ Matplotlib
- matplotlib은 파이썬에서 자료를 차트나 플롯(plot)으로 시각화하는 아주 유용한 패키지이다.
- matplotlib은 아래와 같은 그래프를 제공하여 다양한 시각화 기능을 제공한다.
- 막대 그래프 (bar)
- 선 그래프(line)
- 산포도(scatter)
- 상자(box)
- 히스트그램(histogram)
- matplotlib 웹사이트
Matplotlib: Python plotting — Matplotlib 3.2.1 documentation
matplotlib.org
기본 그래프
데이터의 종류에 알맞게 그래프를 선택
1) 정적 데이터
- 요약 방법 : 도표
- 정리 방법 : 도수분포표, 분할표
- 그래프 : 막대그래프 , 원그래프
2) 양적 데이터
- 요약 방법 : 수치
- 정리 방법 : 산술 평균, 중앙값...
- 그래프 : 히스토그램, Boxplot, 시계열 그래프, 산포도(산점도)
matplotlib모듈을 사용하려면 우선 패키지를 설치해야 한다.
pip install matplotlib
설치 이후 패키지 사용
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplab as plt ← pylab 서브 패키지
▶▷▶ mpl / plt 별칭은 관례이다.
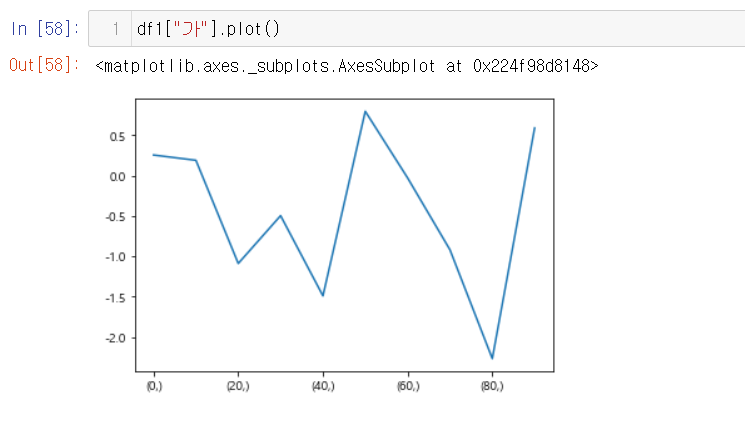
1. 선 그래프(lineplot)
- 가장 간단한 그래프
- 데이터가 시간, 순서 등에 따라 어떻게 변화하는지를 보여주기 위함
-
배열을 선 그래프로 시각화

-
데이터 프레임을 선 그래프로 시각화

- 시각화한 데이터베이스 인덱스
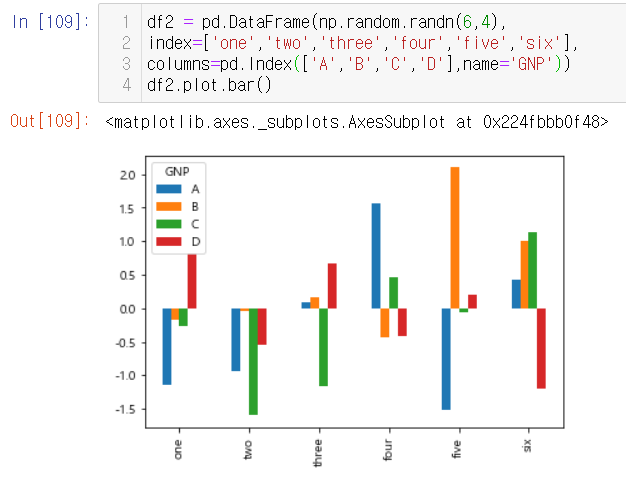
2. 막대 그래프 (bar plot)
- x 축 데이터가 카테고리 값인 경우 사용
- 기본 막대 그래프 (bar plot)

- 가로 방향 막대 그래프 (barh plot)

- 데이터 프레임을 막대그래프(bar)로 시각화
- 데이터 프레임을 가로 막대그래프(barh)로 시각화- stacked=True : 막대그래프를 쌓아서 표시

3. 히스토그램(histogram)
- X변수가 가질 수 있는 값의 범위 값만 필요하고 인덱스는 필요 없다.(y변수만 필요)
- 연속적인 데이터를 표시할 때 사용
- hist()라는 전용 함수를 사용
- 기본 막대 개수 : 10개 (dafualt = 10) # <bins= 개수>로 막대 개수 조절
- hist()를 사용하여 히스토그램 시각화

- bins : 막대 개수 조절

4. 산포도(산점도, Scatter)
- 두 변수의 관계(양, 음)를 나타 낼 때 사용
- 이변령 그래프
- plot.scatter(x좌표, y좌표)

5. Box plot
- 연속형 변수와 이산형 변수를 함께 그리는 그래프
- 다변령 그래프
- 기본적으로 4분 위수 표현
- 범위를 벗어난 값 = 이상치
- median(중앙값)을 표시
- plot.box()를 사용하여 시각화

'파이썬\python > 데이터 시각화' 카테고리의 다른 글
| <파이썬 데이터 시각화>Seaborn(sns)를 이용한 시각화 (2) | 2020.06.24 |
|---|






















